I’ve been collecting funny images on now-closed Soup.io service since 2009. It was a great place, with people gathering funny, insightful or in other way interesting images (and texts and videos) on site with easy reposting, similar to Tumblr but more convenient. My soup was pretty impactful, up to inspiring Dymitr Gloutchenko – we were coworkers at that time – to launch his own kwejk.pl which used my soup as the starting seed for the first few months.
But it did come to an end. Soup was shut down in July 2020, and despite inability to download a complete XML feed of my account, I managed to download it all using soupscraper by Nathell and set up a self-hosted archive at soup.tomash.eu. I continue collecting images from the internet on a new service, Loforo, which is a very nice soup successor, where I also have that complete soup archive.
Anyway, that’s a lot of time and a lot of images, around 33 000 (that’s way OVER NINE THOUSAND!), with no way to search through their contents. I’d love to have descriptions for all those images about what’s in them, fed into a proper full-text search engine. For reference, nostalgia and the infamous lulz. But I’m not spending weeks going through the entire collection and writing those descriptions, ain’t nobody got time for that.
2024 comes to an end. Vision-enabled Large Language Models are not only available but some are also open-source and can be ran on consumer-grade hardware, so the costs can be kept under control. gpt-4o-mini would cost me approximately 80 USD for processing the entire archive, let’s see if I can have it cheaper by running a model myself. This way or another, I want a machine to do those descriptions for me!
After some googling I’ve decided to process all those images using the open llama3.2-vision:11b model and run it under ollama on my gaming machine with Radeon RX 6800. One short Python script later, written mostly by prompting Copilot (since my Python knowledge is tiny), I was ready to go.
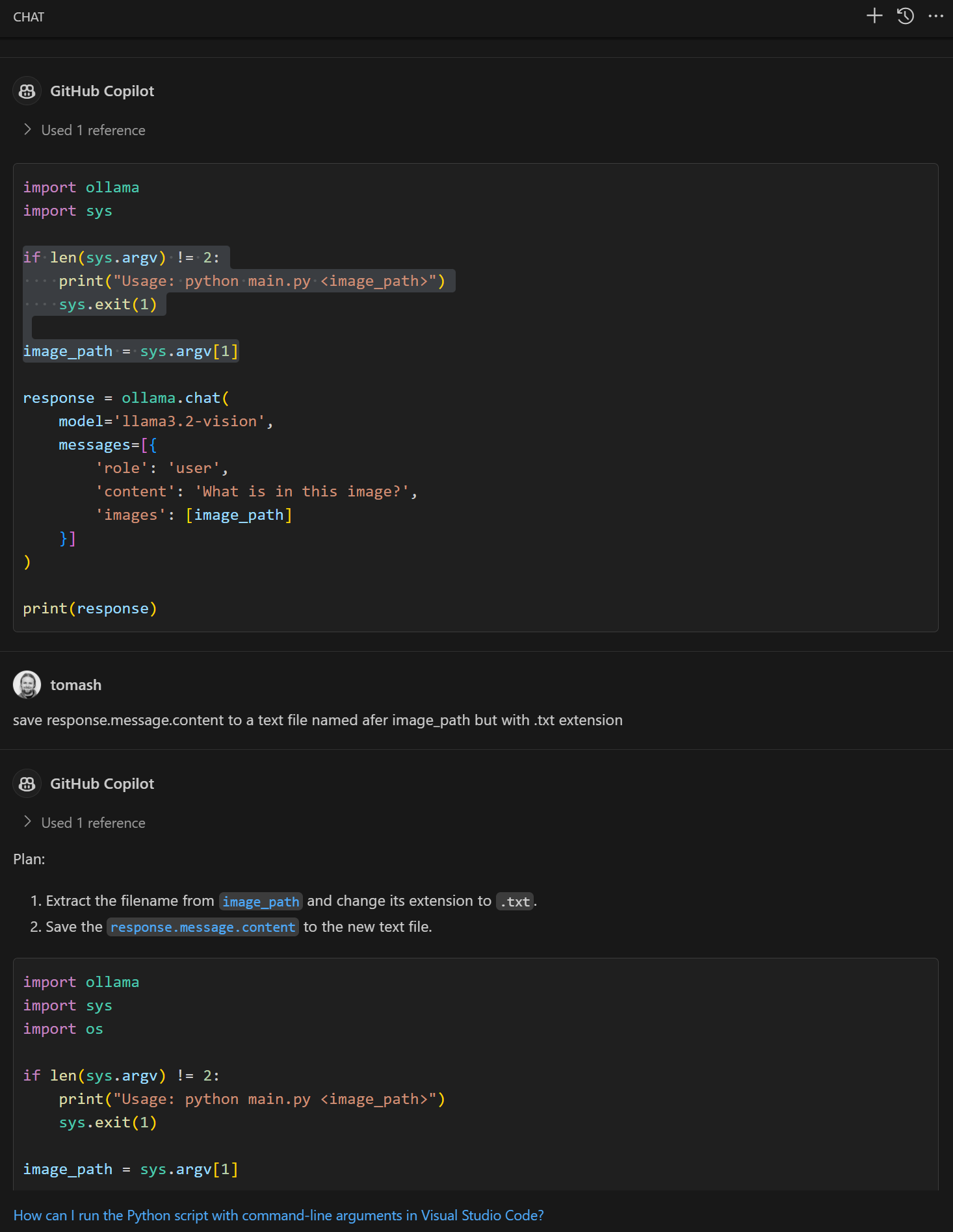 Asking Copilot to write some Python
Asking Copilot to write some Python
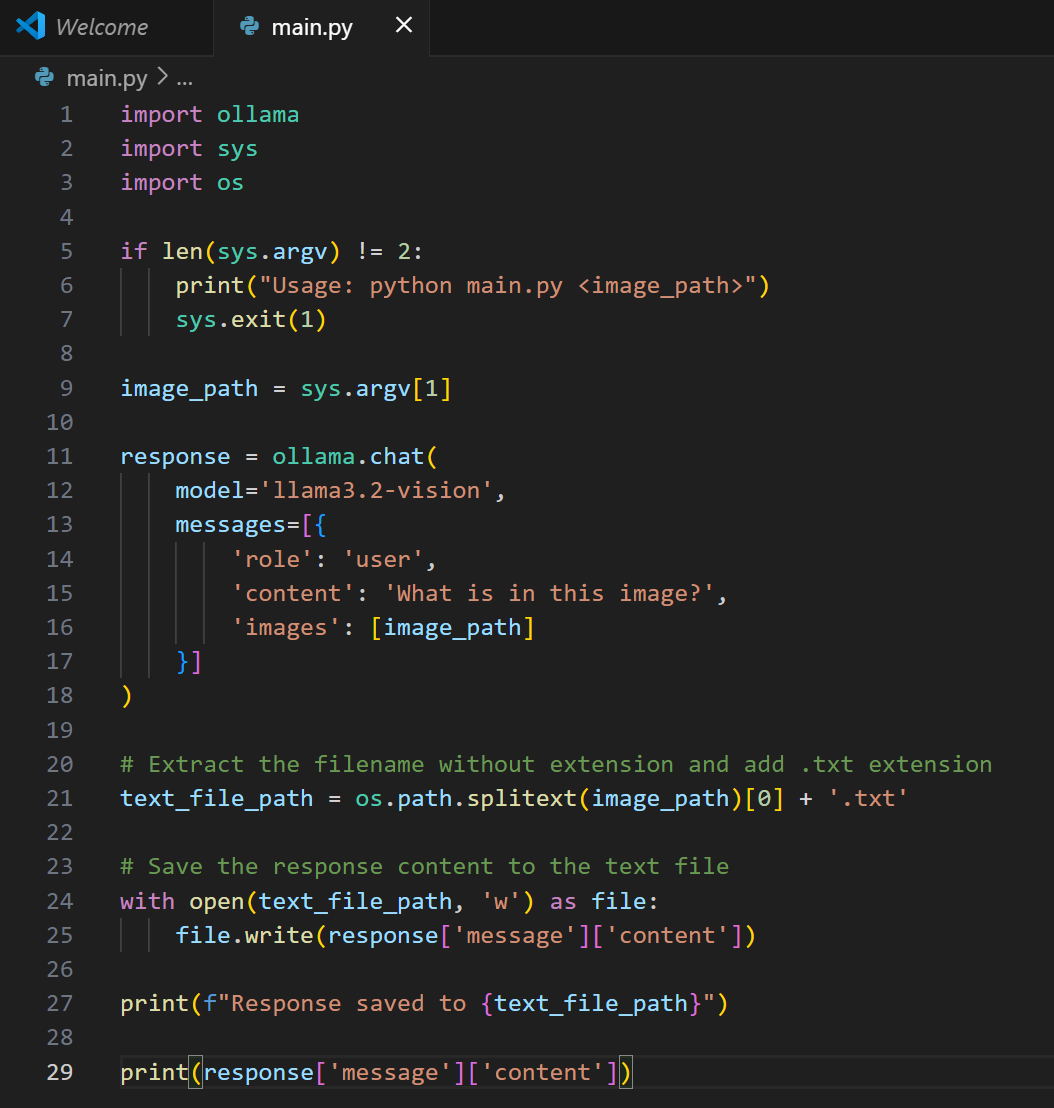 Some Python written mostly by Copilot
Some Python written mostly by Copilot
I did not research enough and thought that 16GB of VRAM should be enough for a 11B model, so I was pretty disappointed to find out that after one night only around 1k of images have been processed. So after some more googling I’ve registered on NodeShift and started to run llama3.2-vision:11b on a beefier GPU there, managing to process a few more thousand of the images, but with more frustrations since the instances had an irritating tendency to become “exited” (dead) after a few hours, which made me restart the whole process every single time (including uploading ~11 GB of images).
After having around 14k images described by Llama and becoming frustrated, even willing to switch to an external, paid API, I’ve stumbled upon a thread where someone said that Claude 3 Haiku is both a very fast and very cheap vision-enabled model. I ran a few numbers, uploaded a few images and it looked almost too good to be true. And since my Anthropic account had around 9 USD left from my Cursor+Claude experiments, I’ve decided to give it a go. It was blazing fast! The remaining 18k images have been described within one day and the descriptions were of better quality than ones from llama3.2-vision:11b. Llama was generally okay but sometimes it hilariously misunderstood the image and hallucinated the description, with my favourite example being this one:

While the models were busy generating descriptions, I went on looking on how to make a fully client-side full-text search that could be fed with a generated JSON file (with all the descriptions). It had to be client-side because my soup archive runs on a humble Atomic Pi, a single-board computer with Intel Atom x5-Z8350 I bought back in 2019. I just really, really don’t want it to run anything server-side. 33k images with up to 1kB of description per image should mean that the index JSON should be within 35MB, pretty heavy but nothing back-breaking for modern hardware, especially comparing to average site happily eating over 200MB of RAM. And again thanks to Nathell I learned about lunr.js which is small, lean, solr-inspired and all within 29kB of minified JavaScript. With a Copilot prompts, some tests and corrections, I hacked together a simplest possible search page that goes over those descriptions. And we’re done here!
Full-text search of images from tomash.soup.io archive based on their LLM-generated descriptions
Disclaimer and Content Warning! 2009 was 15 years ago I was 25 years old back then. Some things that were funny to me at that age are not funny to me anymore, and vice versa. Some images are there because I reposted them with a facepalm (the comments were lost during the migration) or due to their sheer edgy-ness, despite being wrong. Some of them are really dark humor, or really inappropiate in a multitude of ways. 4chan was big back then. You are entering at your own risk. There’s a lot of potential triggers there.
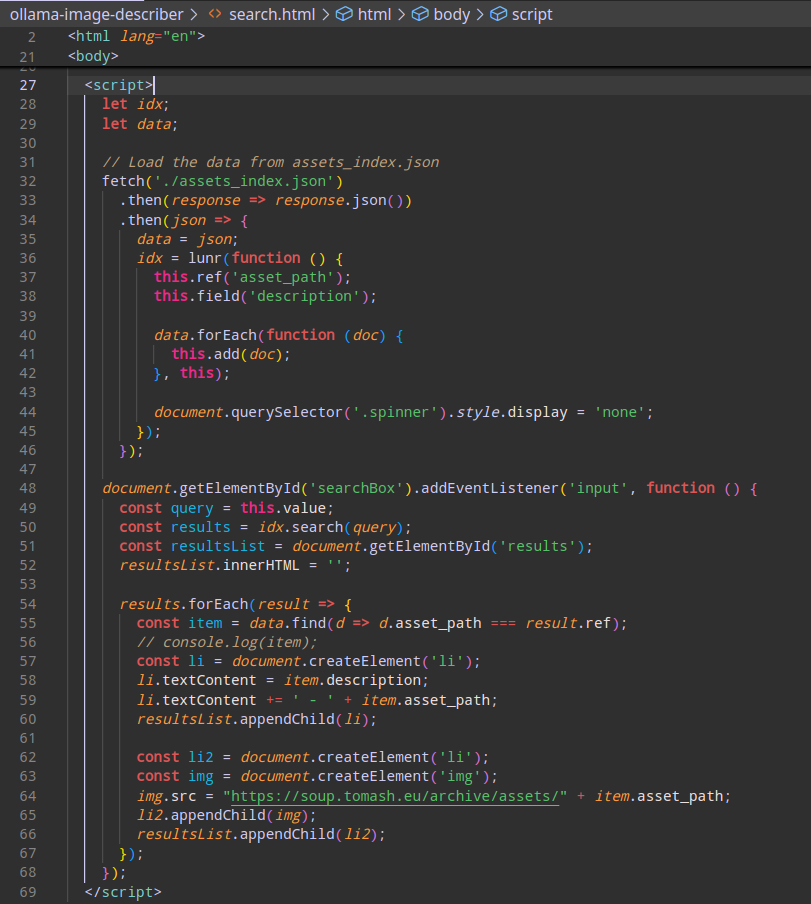
Here’s the entire code that uses Lunr.js, pure JS without a touch of frameworks nor any node/npm.
Epilogue. 2009-2020 is 12 years, but there are 16 years in the title? Yes, I am planning to do the same with images I’ve posted to Loforo since July 2020 up to this day. But that’s going to happen next year at the soonest. Have a happy 2025 everyone!
Some social media entries as I went along with this work below.
https://bsky.app/profile/tomash.eu/post/3ldmgjm2mgc2e
https://bsky.app/profile/tomash.eu/post/3ldqp2iaay22z
https://bsky.app/profile/tomash.eu/post/3ldvvcowdmw2c